JavaScript is a bit like The Faceless Men of the programming world.
It can be Asynchronous. It can be Functional. It can be Object-oriented. It can be Client-side. It can be Server-side. The list goes on.
This article will focus on Asynchronous JavaScript.
But wait, JavaScript is a synchronous language!
This means only one operation can be carried out at a time. But that’s not the entire picture here. There are many ways JavaScript provides us with the ability to make it behave like an asynchronous language. One of them is with the Async-Await clause.
What is async-await?
Async and Await are extensions of promises. If you are not clear with the concepts of Promise, you can refer my previous post How to write Promises in JavaScript.
Async
Async functions enable us to write promise based code as if it were synchronous, but without blocking the execution thread. It operates asynchronously via the event-loop. Async functions will always return a value. Using async simply implies that a promise will be returned, and if a promise is not returned, JavaScript automatically wraps it in a resolved promise with its value.
async function firstAsync() {
return 27;
}
firstAsync().then(alert); // 27
Running the above code gives the alert output as 27, it means that a promise was returned, otherwise the .then() method simply would not be possible.
Await
The await operator is used to wait for a Promise. It can be used inside an Async block only. The keyword Await makes JavaScript wait until the promise returns a result. It has to be noted that it only makes the async function block wait and not the whole program execution.
The code block below shows the use of Async Await together.
async function firstAsync() {
let promise = new Promise((res, rej) => {
setTimeout(() => res("Now it's done!"), 1000)
});
// wait until the promise returns us a value
let result = await promise;
// "Now it's done!"
alert(result);
}
};firstAsync();
Things to remember when using Async Await
We can’t use the await keyword inside of regular functions.
function firstAsync() {
let promise = Promise.resolve(10);
let result = await promise; // Syntax error
}
To make the above function work properly, we need to add async before the function firstAsync();
Async Await makes execution sequential
Not necessarily a bad thing, but having paralleled execution is much much faster.
For example:
async function sequence() {
await promise1(50); // Wait 50ms…
await promise2(50); // …then wait another 50ms.
return "done!";
}
The above takes 100ms to complete, not a huge amount of time but still slow.
This is because it is happening in sequence. Two promises are returned, both of which takes 50ms to complete. The second promise executes only after the first promise is resolved. This is not a good practice, as large requests can be very time consuming. We have to make the execution parallel.
That can be achieved by using Promise.all() .
According to MDN:
The Promise.all() method returns a single Promise that resolves when all of the promises passed as an iterable have resolved or when the iterable contains no promises. It rejects with the reason of the first promise that rejects.
Promise.all()
async function sequence() {
await Promise.all([promise1(), promise2()]);
return "done!";
}
The promise.all() function resolves when all the promises inside the iterable have been resolved and then returns the result.
Another method:
async function parallel() { // Start a 500ms timer asynchronously…
const wait1 = promise1(50); // …meaning this timer happens in parallel.
const wait2 = promise2(50);
// Wait 50ms for the first timer…
await wait1;
// …by which time this timer has already finished.
await wait2;
return "done!";}
Async Await is very powerful but they come with caveats. But if we use them properly, they help to make our code very readable and efficient.
I hope you have learned something new! If you found this article useful, be sure to share, clap, follow and support!
Almost anyone who has used JavaScript, had a love/hate relationship with it at some point. JavaScript is like that girlfriend who is frustrating at times but has something about her which keeps us intrigued. JavaScript has a galore of interesting topics and concepts to explore. Let’s start with one of them- Promises.
JavaScript is a synchronous programming language, but because of callback functions we can make it work like an Asynchronous Programming language.
Promises
Promises in javascript are very similar to promises made in real life.
Definition of promise -Google
After a promise is made, we get an assurance about ‘something’ and we can plan accordingly.
They can be kept or broken.
We can’t act on them immediately. Only after the promise is kept.
The executing function(executor) accepts two parameters resolve and reject which in turn are callback functions. Promises are used for handling asynchronous operations also called blocking code, examples of which are DB, I/O or API calls, which are carried out by the executor function. Once that completes it either calls resolve on success or reject function on error.
Simple example
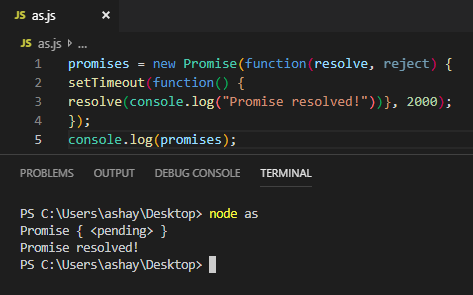
let promise = new Promise(function(resolve, reject) {if(promise_kept)
resolve("done");else
reject(new Error("…"));
});
As it can be seen, Promises don’t return values immediately. It waits for the success or failure and then returns accordingly. This lets asynchronous methods return values like synchronous ones. Instead of returning values right away, async methods supply a promise to return the value.
The above paragraph makes one thing clear, It has states!
A promise can be one of these states-
pending — This is the initial state or state during execution of promise. Neither fulfilled nor rejected.
fulfilled — Promise was successful.
rejected — Promise failed.
The states are quite self-explanatory so won’t go in detail. Here is a screenshot for reference.
Handling and Consuming the Promise
In the last section we saw how Promises are created, now let’s see how the promise can be consumed.
Running .checkIfDone() will execute the isDone() promise and will wait for it to resolve, using the then callback. If there is an error it will be handled in the catch block.
Chaining Promises
A promise can be returned to another promise , creating a chain of promises. If one fails all others too. Chaining is very powerful combined with Promise as it gives us the control of the order of events in our code.
new Promise(function(resolve, reject) {
setTimeout(() => resolve(1), 1000);
}).then(function(result) {
alert(result);
return result * 3;
}).then(function(result) {
alert(result);
return result * 4;
}).then(function(result) {
alert(result);
return result * 6;
});
All of the operations return there results to the next then() function on resolve and this process continues till the chain is complete. The last element in the chain return the final result.
Conclusion
This was just a basic gist of JavaScript promises. Promises can do a lot more if used in the right way and the right place.
Writing asynchronous applications in Node.js can be hard to learn, but except for some really simple cases, it cannot be avoided. Accessing a database is an example of an operation which is asynchronous by nature. It means that you have to wait for the results of a query, but while waiting, your program will continue to execute. For example, it can do some calculations or send another query to the database in parallel.
In a traditional, synchronous programming language like PHP, you could simply write:
$result = $connection->query( 'SELECT * FROM users WHERE id = 1' );
In JavaScript, you have three options to write asynchronous code:
1. Using callbacks:
db.query( 'SELECT * FROM users WHERE id = 1', ( err, rows ) => {
// ... use the result ...
} );
2. Using promises:
db.query( 'SELECT * FROM users WHERE id = 1' ).then( rows => {
// ... use the result ...
} );
3. Using the await keyword:
const rows = await db.query( 'SELECT * FROM users WHERE id = 1' );
At first, the difference seems purely cosmetic. It’s just different syntax for achieving the same thing. The differences become more obvious when you try to do something more complex.
Limitations of callbacks and promises
In my earlier article, Node.js, MySQL and promises, I gave an example of executing a few queries, one after another, and subsequently closing the connection.
When using plain callbacks, this requires nesting the callback functions and checking the error result in each function, which leads to a “callback hell”.
With promises, the code becomes more elegant, because you can chain multiple then() handlers and use one catch() handler for all errors. However, extracting the query results and closing the connection regardless of a success or error still requires some effort.
The situation becomes even worse when you have to introduce loops and conditions into an asynchronous code. Imagine the following hypothetical synchronous pseudocode:
const users = db.query( 'SELECT * FROM users WHERE id = 1' );
for ( const i in users ) {
users[ i ].groups = db.query( '...' );
if ( users[ i ].is_admin )
users[ i ].modules = db.query( '...' );
}
Implementing this code asynchronously with callbacks would be hard and would make the code almost unreadable. Unfortunately, promises don’t make this much easier:
db.query( ‘SELECT * FROM users WHERE id = 1' ).then( users => {
let loop = Promise.resolve();
for ( const i in users ) {
loop = loop.then( () => db.query( '...' )
.then( groups => users[ i ].groups = groups ) );
if ( users[ i ].is_admin ) {
loop = loop.then( () => db.query( '...' )
.then( members => users[ i ].members = members ) );
}
}
return loop.then( () => users );
} );
The above code would probably work as intended, but it’s not very readable. When asynchronous operations are dynamically chained like this, it’s hard to determine the order in which they will be executed.
The async/await way
Here’s the same code implemented using the await keyword:
const users = await db.query( 'SELECT * FROM users WHERE id = 1' );
for ( const i in users ) {
users[ i ].groups = await db.query( '...' );
if ( users[ i ].is_admin )
users[ i ].modules = await db.query( '...' );
}
As you can see, it’s almost identical to the synchronous example. It uses traditional programming constructs, such as loop and conditionals, and the execution order becomes obvious. That’s why it’s very easy to read and write such code.
Error handling is also more explicit, because you can use constructs like try/catch and try/finally. This makes it easier to see which error handler is associated with a particular block of code.
When you are just beginning to use it, the async/await syntax seems like some dark magic. It’s important to understand that it’s actually just syntactic sugar for regular promises which are used behind the scenes. This means that you can freely mix promises with async/await.
An async function is simply nothing more than a function that is guaranteed to return a promise. You can use it like any other function which returns a promise:
async function foo() {
return 42;
}foo().then( result => console.log( result ) );
This code will print 42.
On the other hand, within an async function, you can use the await keyword with any promise, not only to call other async functions:
This is very important, because we can wrap any existing function which uses callbacks to return a promise, and call that function using the async/await syntax.
It’s similar to the Database class I implemented in the previous article, only this time it’s a factory function instead of a class, and it uses the promisify() utility function to keep things simple. But it works the same, so both the query() and close() functions return a promise.
The example code from the previous article can be rewritten using async/await:
const db = makeDb( config );
try {
const someRows = await db.query( 'SELECT * FROM some_table' );
const otherRows = await db.query( 'SELECT * FROM other_table' );
// do something with someRows and otherRows
} catch ( err ) {
// handle the error
} finally {
await db.close();
}
We can add support for transactions by promisifying the beginTransaction(), commit() and rollback() functions in our database wrapper:
As you can see, the callback parameter is expected to be a function returning a promise.
With this helper function, the above code can be simplified to this:
const db = makeDb( config );
try {
await withTransaction( db, async () => {
const someRows = await db.query( 'SELECT * FROM some_table' );
const otherRows = await db.query( 'SELECT * FROM other_table' );
// do something with someRows and otherRows
} );
} catch ( err ) {
// handle error
}
Here we use the async keyword with an arrow function to easily create an asynchronous callback function.
Final notes
From my experience, once you get used to writing code using async/await, it’s hard to imagine how you could live without it. However, to be able to write asynchronous code, you still need to understand promises, and in order to use promises, you need to understand callbacks.
Note that the async/await syntax only works in Node.js version 8 or newer, so if you are still using an older version, you should consider updating it.
You can also use async/await in client side code if you are targetting modern browsers. If you have to support IE, it’s also possible with the help of transpilers and polyfills, but that’s outside of the scope of this article.
JavaScript is a single-threaded programming language which means only one thing can happen at a time. That is, the JavaScript engine can only process one statement at a time in a single thread.
While the single-threaded languages simplify writing code because you don’t have to worry about the concurrency issues, this also means you can’t perform long operations such as network access without blocking the main thread.
Imagine requesting some data from an API. Depending upon the situation the server might take some time to process the request while blocking the main thread making the web page unresponsive.
That’s where asynchronous JavaScript comes into play. Using asynchronous JavaScript (such as callbacks, promises, and async/await), you can perform long network requests without blocking the main thread.
While it’s not necessary that you learn all these concepts to be an awesome JavaScript developer, it’s helpful to know 🙂
So without further ado, Let’s get started 🙂
Tip: Using Bit you can turn any JS code into an API you can share, use and sync across projects and apps to build faster and reuse more code. Give it a try.
Component Discovery and Collaboration · Bit
Bit is where developers share components and collaborate to build amazing software together. Discover components shared…
bit.dev
How Does Synchronous JavaScript Work?
Before we dive into asynchronous JavaScript, let’s first understand how the synchronous JavaScript code executes inside the JavaScript engine. For example:
const second = () => {
console.log('Hello there!');
}const first = () => {
console.log('Hi there!');
second();
console.log('The End');
}first();
To understand how the above code executes inside the JavaScript engine, we have to understand the concept of the execution context and the call stack (also known as execution stack).
Execution Context
An Execution Context is an abstract concept of an environment where the JavaScript code is evaluated and executed. Whenever any code is run in JavaScript, it’s run inside an execution context.
The function code executes inside the function execution context, and the global code executes inside the global execution context. Each function has its own execution context.
Call Stack
The call stack as its name implies is a stack with a LIFO (Last in, First out) structure, which is used to store all the execution context created during the code execution.
JavaScript has a single call stack because it’s a single-threaded programming language. The call stack has a LIFO structure which means that the items can be added or removed from the top of the stack only.
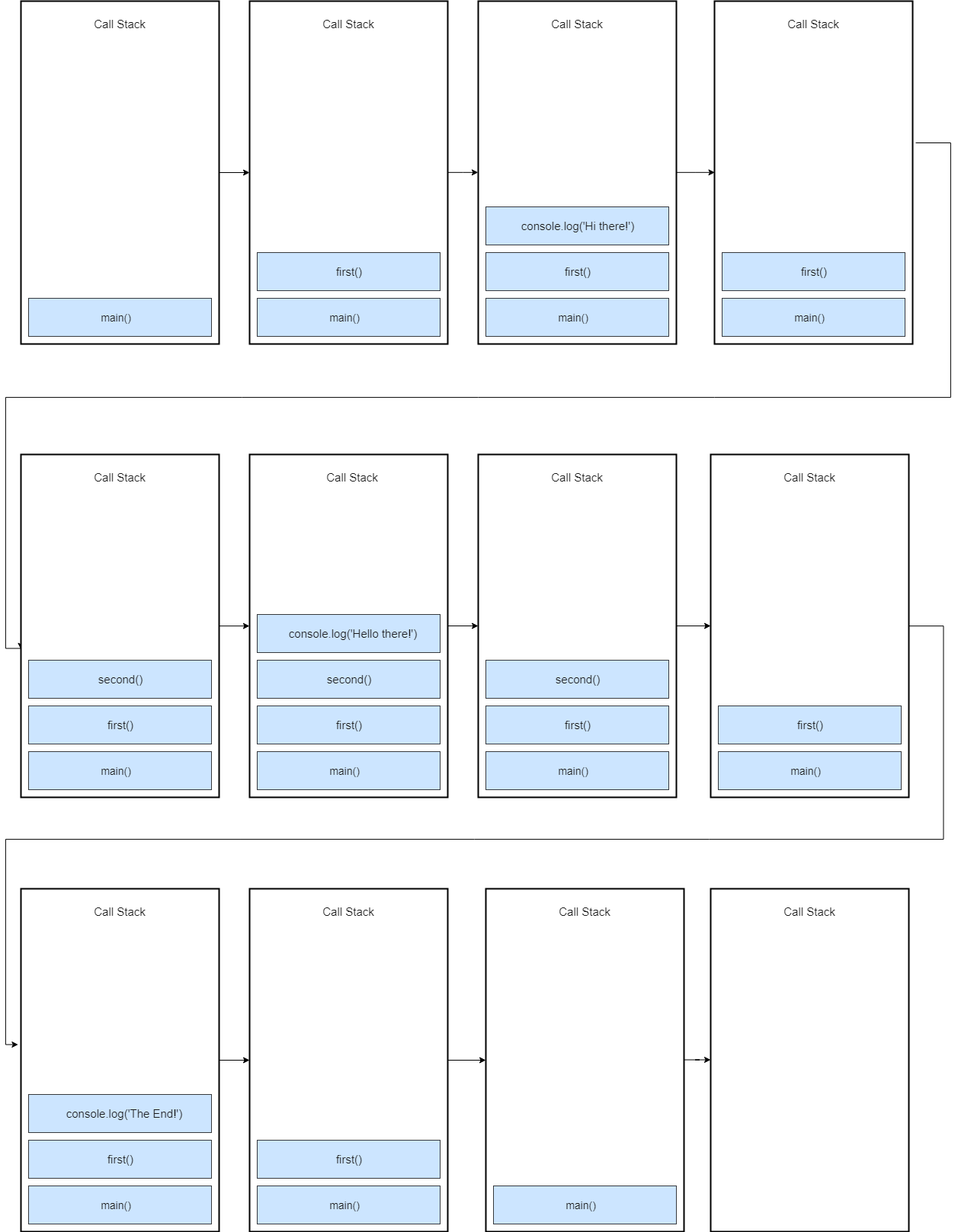
Let’s get back to the above code snippet and try to understand how the code executes inside the JavaScript engine.
const second = () => {
console.log('Hello there!');
}const first = () => {
console.log('Hi there!');
second();
console.log('The End');
}first();
Call Stack for the above code
So What’s Happening Here?
When this code is executed, a global execution context is created (represented by main()) and pushed to the top of the call stack. When a call to first() is encountered, it’s pushed to the top of the stack.
Next, console.log('Hi there!') is pushed to the top of the stack, when it finishes, it’s popped off from the stack. After it, we call second(), so the second() function is pushed to the top of the stack.
console.log('Hello there!') is pushed to the top of the stack and popped off the stack when it finishes. The second() function finishes, so it’s popped off the stack.
console.log(‘The End’) is pushed to the top of the stack and removed when it finishes. After it, the first() function completes, so it’s removed from the stack.
The program completes its execution at this point, so the global execution context(main()) is popped off from the stack.
How Does Asynchronous JavaScript Work?
Now that we have a basic idea about the call stack, and how the synchronous JavaScript works, let’s get back to the asynchronous JavaScript.
What is Blocking?
Let’s suppose we are doing an image processing or a network request in a synchronous way. For example:
Doing image processing and network request takes time. So when processImage() function is called, it’s going to take some time depending on the size of the image.
When the processImage() function completes, it’s removed from the stack. After that the networkRequest() function is called and pushed to the stack. Again it’s also going to take some time to finish execution.
At last when the networkRequest() function completes, greeting() function is called and since it contains only a console.log statement and console.log statements are generally fast, so the greeting() function is immediately executed and returned.
So you see, we have to wait until the function (such as processImage() or networkRequest()) has finished. This means these functions are blocking the call stack or main thread. So we can’t perform any other operation while the above code is executing which is not ideal.
So what’s the solution?
The simplest solution is asynchronous callbacks. We use asynchronous callbacks to make our code non-blocking. For example:
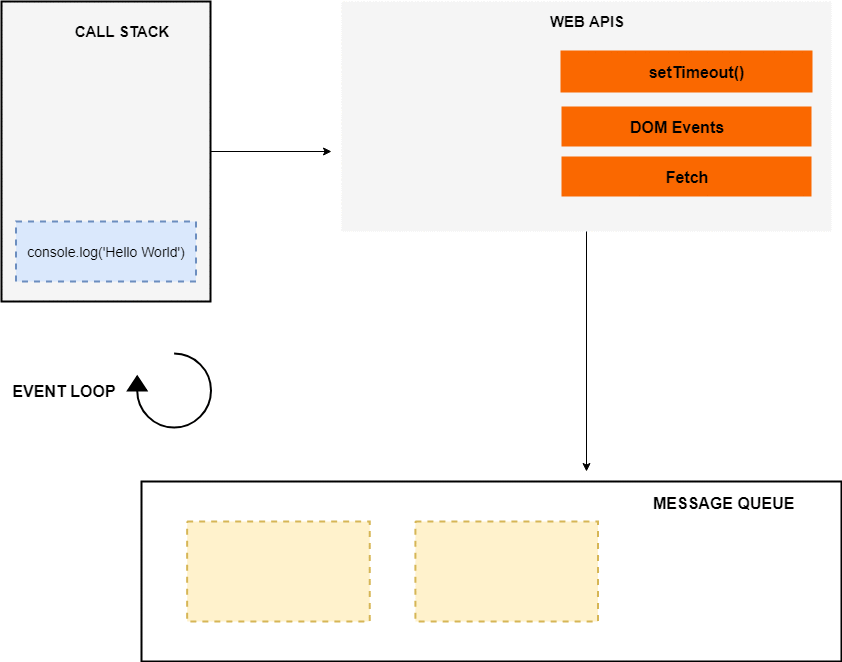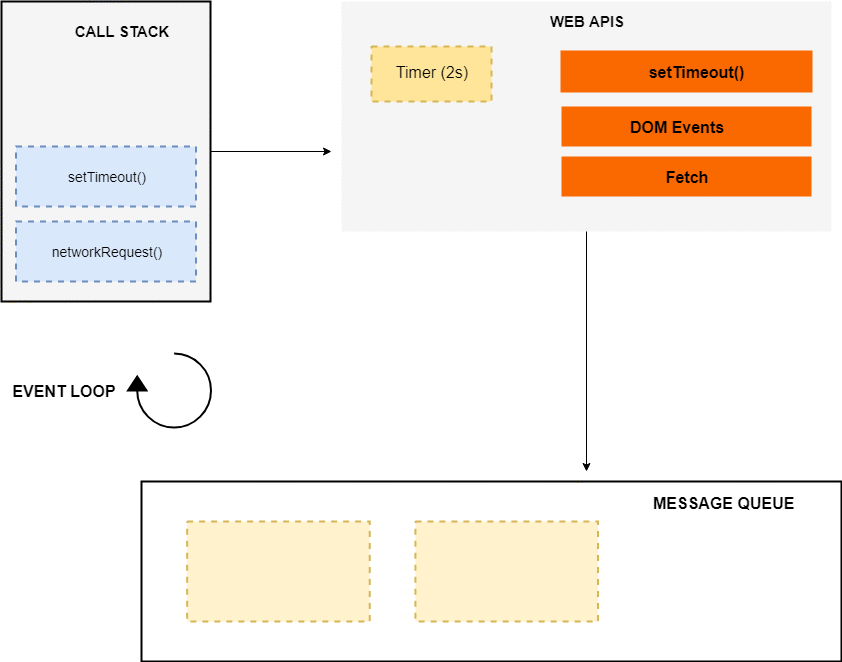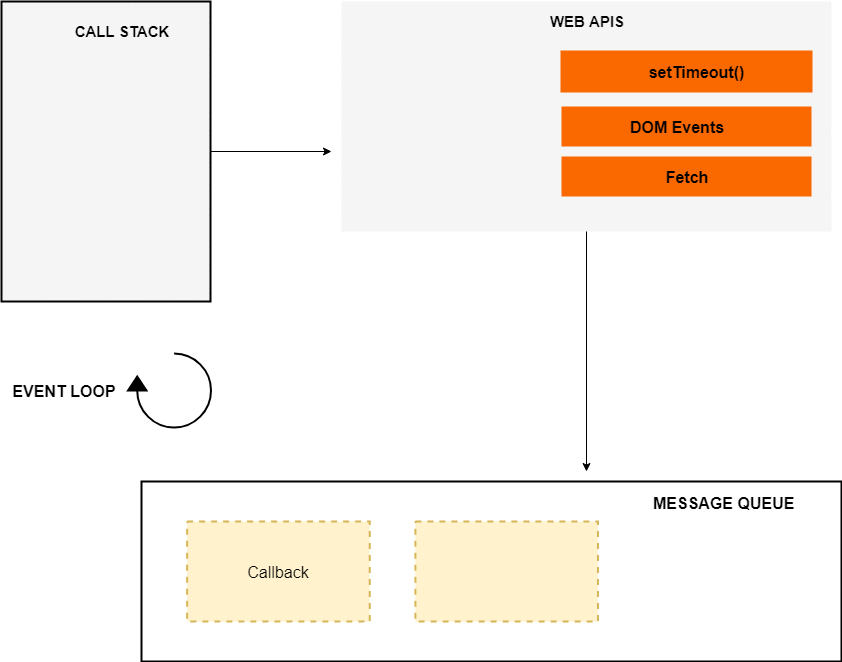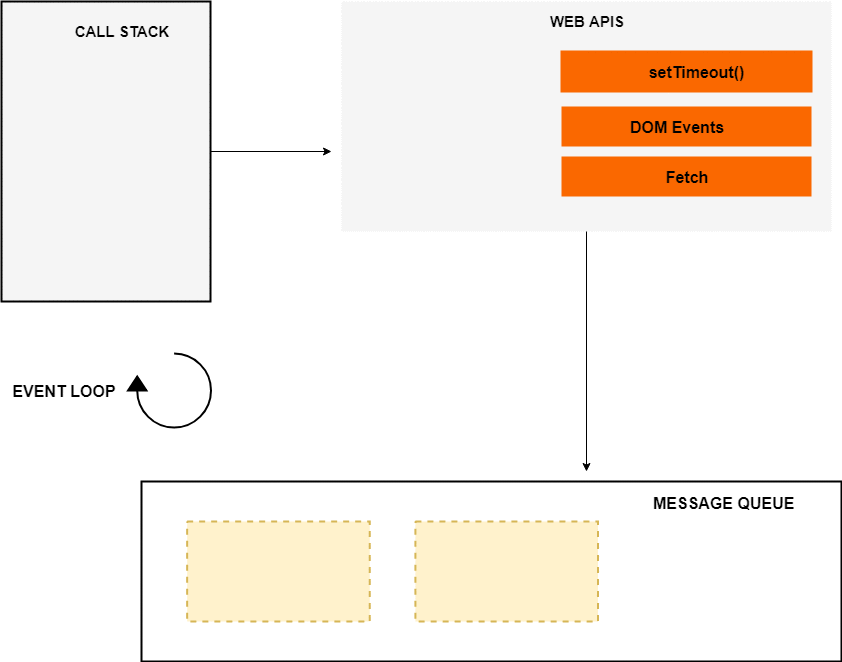
Here I have used setTimeout method to simulate the network request. Please keep in mind that the setTimeout is not a part of the JavaScript engine, it’s a part of something known as web APIs (in browsers) and C/C++ APIs (in node.js).
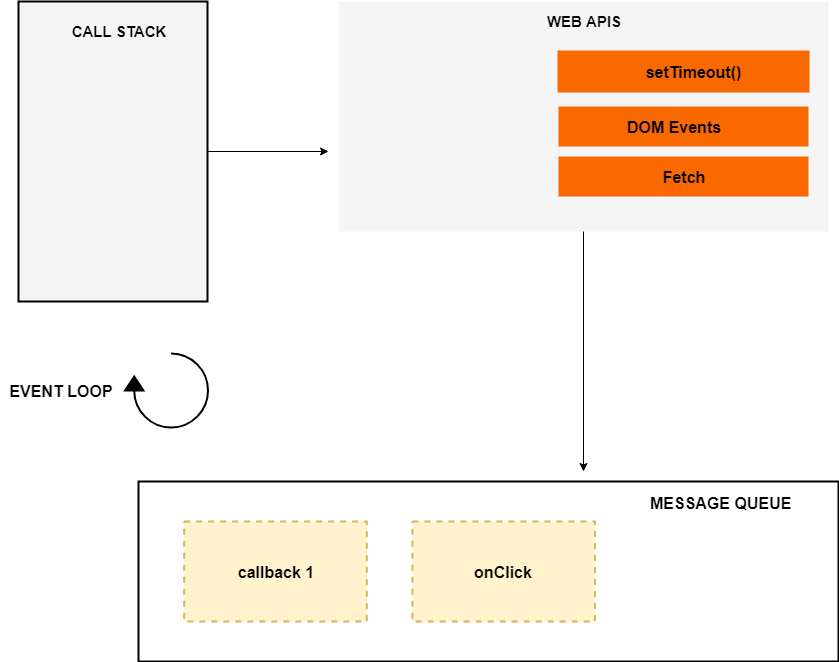
To understand how this code is executed we have to understand a few more concepts such event loop and the callback queue (also known as task queue or the message queue).
An Overview of JavaScript Runtime Environment
The event loop, the web APIs and the message queue/task queue are not part of the JavaScript engine, it’s a part of browser’s JavaScript runtime environment or Nodejs JavaScript runtime environment (in case of Nodejs). In Nodejs, the web APIs are replaced by the C/C++ APIs.
Now let’s get back to the above code and see how it’s executed in an asynchronous way.
When the above code loads in the browser, the console.log(‘Hello World’) is pushed to the stack and popped off the stack after it’s finished. Next, a call to networkRequest() is encountered, so it’s pushed to the top of the stack.
Next setTimeout() function is called, so it’s pushed to the top of the stack. The setTimeout() has two arguments: 1) callback and 2) time in milliseconds (ms).
The setTimeout() method starts a timer of 2s in the web APIs environment. At this point, the setTimeout() has finished and it’s popped off from the stack. After it, console.log('The End') is pushed to the stack, executed and removed from the stack after its completion.
Meanwhile, the timer has expired, now the callback is pushed to the message queue. But the callback is not immediately executed, and that’s where the event loop kicks in.
The Event Loop
The job of the Event loop is to look into the call stack and determine if the call stack is empty or not. If the call stack is empty, it looks into the message queue to see if there’s any pending callback waiting to be executed.
In this case, the message queue contains one callback, and the call stack is empty at this point. So the Event loop pushes the callback to the top of the stack.
After that the console.log(‘Async Code’) is pushed to the top of the stack, executed and popped off from the stack. At this point, the callback has finished so it’s removed from the stack and the program finally finishes.
DOM Events
The Message queue also contains the callbacks from the DOM events such as click events and keyboard events. For example:
In case of DOM events, the event listener sits in the web APIs environment waiting for a certain event (click event in this case) to happen, and when that event happens, then the callback function is placed in the message queue waiting to be executed.
Again the event loop checks if the call stack is empty and pushes the event callback to the stack if it’s empty and the callback is executed.
We have learned how the asynchronous callbacks and DOM events are executed which uses the message queue to store all the callbacks waiting to be executed.
ES6 Job Queue/ Micro-Task queue
ES6 introduced the concept of job queue/micro-task queue which is used by Promises in JavaScript. The difference between the message queue and the job queue is that the job queue has a higher priority than the message queue, which means that promise jobs inside the job queue/ micro-task queue will be executed before the callbacks inside the message queue.
Script start
Script End
Promise resolved
setTimeout
We can see that the promise is executed before the setTimeout, because promise response are stored inside the micro-task queue which has a higher priority than the message queue.
Let’s take another example, this time with two promises and two setTimeout. For example:
We can see that the two promises are executed before the callbacks in the setTimeout because the event loop prioritizes the tasks in micro-task queue over the tasks in message queue/task queue.
While the event loop is executing the tasks in the micro-task queue and in that time if another promise is resolved, it will be added to the end of the same micro-task queue, and it will be executed before the callbacks inside the message queue no matter for how much time the callback is waiting to be executed.
So all the tasks in micro-task queue will be executed before the tasks in message queue. That is, the event loop will first empty the micro-task queue before executing any callback in the message queue.
Conclusion
So we have learned how asynchronous JavaScript works and other concepts such as call stack, event loop, message queue/task queue and job queue/micro-task queue which together make the JavaScript runtime environment. While it’s not necessary that you learn all these concepts to be an awesome JavaScript developer, but it’s helpful to know these concepts 🙂
I have been doing day-to-day code reviews for over a decade now. The benefits of code reviews are plenty: someone spot checks your work for errors, they get to learn from your solution, and the collaboration helps to improve the organization’s overall approach to tooling and automation. If you’re not currently doing code reviews in your organization, start now. It’ll make everyone a better engineer.
Plenty of people and organizations have shared their code review best practices and what the definition of good code reviews mean to them. Guides from Google, the SmartBear team, and engineer Philipp Hauerare all excellent reads. Below is my personal take on what good code reviews look like and how to make them even better at the team and organizational level. This is in the context of the tech environment I have been working at – currently at Uber, and before that at Skype/Microsoft and Skyscanner.
Good code reviews are the bar that all of us should strive for. They cover common and easy to follow best practices that any team can get started with, while ensuring high-quality and helpful reviews for the long term.
Better code reviews are where engineers keep improving how they do code reviews. These code reviews look at the code change in the context of the codebase, of who is requesting it and in what situation. These reviews adjust their approach based on the context and situation. The goal not only being a high-quality review, but also to help the developers and teams requesting the review to be more productive.
Areas Covered by the Code Review
Good code reviews look at the change itself and how it fits into the codebase. They will look through the clarity of the title and description and “why” of the change. They cover the correctness of the code, test coverage, functionality changes, and confirm that they follow the coding guides and best practices. They will point out obvious improvements, such as hard to understand code, unclear names, commented out code, untested code, or unhandled edge cases. They will also note when too many changes are crammed into one review, and suggest keeping code changes single-purposed or breaking the change into more focused parts.
Better code reviews look at the change in the context of the larger system, as well as check that changes are easy to maintain. They might ask questions about the necessity of the change or how it impacts other parts of the system. They look at abstractions introduced and how these fit into the existing software architecture. They note maintainability observations, such as complex logic that could be simplified, improving test structure, removing duplications, and other possible improvements. Engineer Joel Kemp describes great code reviews as a contextual pass following an initial, light pass.
Tone of the Review
The tone of code reviews can greatly influence morale within teams. Reviews with a harsh tone contribute to a feeling of a hostile environment with their microaggressions. Opinionated language can turn people defensive, sparking heated discussions. At the same time, a professional and positive tone can contribute to a more inclusive environment. People in these environments are open to constructive feedback and code reviews can instead trigger healthy and lively discussions.
Good code reviews ask open-ended questions instead of making strong or opinionated statements. They offer alternatives and possible workarounds that might work better for the situation without insisting those solutions are the best or only way to proceed. These reviews assume the reviewer might be missing something and ask for clarification instead of correction.
Better code reviews are also empathetic. They know that the person writing the code spent a lot of time and effort on this change. These code reviews are kind and unassuming. They applaud nice solutions and are all-round positive.
Approving vs Requesting Changes
Once a reviewer completes their review, they can either mark it approved, block the review with change requests, or not set a specific status, leaving it in a “not yet approved” state. How reviewers use the approve and request changes statuses is telling of the code reviews.
Good code reviews don’t approve changes while there are open-ended questions. However, they make it clear which questions or comments are non-blocking or unimportant, marking them distinctively. They are explicit when approving a change – e.g. adding a thumbs up comment like “looks good!”. Some places use acronyms like LGTM—these also work, but be aware that newcomers could misinterpret these insider acronyms for something else. Good code reviews are equally explicit when they are requesting a follow-up, using the code review tool or team convention to communicate this.
Better code reviews are firm on the principle but flexible on the practice: sometimes, certain comments are addressed by the author with a separate, follow-up code change. For changes that are more urgent than others, reviewers try to make themselves available for quicker reviews.
From Code Reviews to Talking to Each Other
Code reviews are usually done asynchronously and in writing through a code review tool. This is usually out of convenience, to enable remote code reviews, and to allow multiple people to review the same code change. But when is it time to stop using the tool—however good it might be—and start talking face to face about the code?
Good code reviews leave as many comments and questions as are needed. If the revision does not address all of them, they will note those as well. When the conversation gets into a long back-and-forth, reviewers will try to switch to talking to the author in-person instead of burning more time using the code review tool.
Better code reviews will proactively reach out to the person making the change after they do a first pass on the code and have lots of comments and questions. These people have learned that they save a lot of time, misunderstandings, and hard feelings this way. The fact that there are many comments on the code indicates that there is likely some misunderstanding on either side. These kinds of misunderstandings are easier identified and resolved by talking things through.
Nitpicks
Nitpicks are are unimportant comments, where the code could be merged without even addressing these. These could be things like variable declarations being in alphabetical order, unit tests following a certain structure, or brackets being on the same line.
Good code reviews make it clear when changes are unimportant nitpicks. They usually mark comments like these distinctively, adding the “nit:” prefix to them. Too many of these can become frustrating and take the attention away from the more important parts of the review, so reviewers aim to not go overboard with these.
Better code reviews realize that too many nitpicks are a sign of lack of tooling or a lack of standards. Reviewers who come across these frequently will look at solving this problem outside the code review process. For example, many of the common nitpick comments can be solved via automated linting. Those that cannot can usually be resolved by the team agreeing to certain standards and following them—perhaps even automating them, eventually.
Code Reviews for New Joiners
Starting at a new company is overwhelming for most people. The codebase is new, the style of programming is different than before, and people review your code very differently. So should code reviews be gentler for new starters, to get them used to the new environment, or should they keep the bar just as high, as it is for everyone else?
Good code reviews use the same quality bar and approach for everyone, regardless of their job title, level or when they joined the company. Following the above, code reviews have a kind tone, request changes where needed, and will reach out to talk to reviewers when they have many comments.
Better code reviews pay additional attention to making the first few reviews for new joiners a great experience. Reviewers are empathetic to the fact that the recent joiner might not be aware of all the coding guidelines and might be unfamiliar with parts of the code. These reviews put additional effort into explaining alternative approaches and pointing to guides. They are also very positive in tone, celebrating the first few changes to the codebase that the author is suggesting.
Cross-Office, Cross-Time Zone Reviews
Code reviews get more difficult when reviewers are not in the same location. They are especially challenging when reviewers are sitting in very different time zones. I have had my fair share of these reviews over the years, modifying code owned by teams in the US and Asia, while being based in Europe.
Good code reviews account for the time zone difference when they can. Reviewers aim to review the code in the overlapping working hours between offices. For reviews with many comments, reviewers will offer to chat directly or do a video call to talk through changes.
Better code reviews notice when code reviews repeatedly run into timezone issues and look for a systemic solution, outside the code review framework. Let’s say a team from Europe is frequently changing a service that triggers code reviews from the US-based owner of this service. The system-level question is why these changes are happening so frequently. Are the changes done in the right codebase or should another system be changed? Will the frequency of changes be the same or go down over time? Assuming the changes are done in the right codebase and the frequency will not go down, can the cross-office dependency be broken in some way? Solutions to these kinds of problems are often not simple and could involve refactoring, creating of new services/interfaces or tooling improvements. But solving dependencies like this will make the life of both teams easier and their progress more efficient for the long term, meaning the return on investment is often quite impressive.
Organizational Support
The way companies and their engineering organizations approach code reviews is a big element of how efficient they can be. Organizations that view them as unimportant and trivial end up investing little in making reviews easier. In cultures like this, it might be tempting to just do away with code reviews entirely. Engineers advocating for doing better code reviews might feel isolated, without support from above and eventually give up. The result is an organization where problems continue to repeat and compound upon themselves.
Organizations with good code reviews ensure that all engineers take part in the code review process—even those that might be working on solo projects. They encourage raising the quality bar, and teams facilitate healthy discussions on code review approaches both at the team and org level. These companies often have code review guides for larger codebases that engineers initiated and wrote. Organizations like this recognise that code reviews take up a good chunk of engineers’ time. Many of these companies will add code reviews as expectations to the developer job competencies, expecting senior engineers to spend a larger chunk of their time reviewing the code of others.
Organizations with better code reviews have hard rules around no code making it to production without a code review—just as business logic changes don’t make it to production without automated tests. These organizations have learned that the cost of cutting corners is not worth it; instead, they have processes for expedited reviews for urgent cases. These organizations invest in developer productivity, including working continually to develop more efficient code reviews and tooling improvements. Helpful engineering executives don’t need convincing on the benefits of code reviews and other engineering best practices. Instead, they support initiatives on better tooling or more efficient code review processes that come from teams.
When people come across reviews that feel hostile, they feel they can speak up and have support all-round to resolve the issue. Senior engineers and managers consider code reviews that are not up to the bar just as much of an issue as sloppy code or poor behavior. Both engineers and engineering managers feel empowered to improve how code reviews are done.
Start With Good, Make it Better
Good code reviews already have lots of good effort going into them. They do a thorough review of the change itself, avoid being opinionated with the tone of comments, and make nitpicks clear. They maintain a consistent bar, regardless of who is requesting the review and try to make cross-time zone reviews less painful by paying additional attention to these. Organizations that have good reviews ensure that every developer regularly receives and does code reviews. This is already a high bar—but if you get here, don’t stop. Code reviews are one of the best ways to improve your skills, mentor others, and learn how to be a more efficient communicator.
Get to better code reviews by continuously improving on the details, but also start looking at changes at a high level as well. Be empathetic in the tone of comments and think of ways outside the code review process to eliminate frequent nitpicks. Make code reviews especially welcoming for new starters and look for systemic solutions for painful cross-time zone reviews. Organizations that are forward-looking encourage investing in tooling and process improvements to make code reviews better, reaping more of the benefits.
Is the freelancing life right for you? Here’s the good and the bad for you to consider.
Most full-time, salaried developers wonder what it would be like to go freelance one day. The lure of higher hourly rates and increased flexibility is appealing. Then doubts start to surface: How would I find clients? Would I have to do sales and marketing? How would I do my taxes? Amidst these doubts, the thought bubble fades away, and full-time salaried work seems like the safer option.
This article is for those who’re thinking more seriously about the possibility of going freelance. It’s for people who want to assemble solid answers to questions like “If I go freelance, how much should I charge?”
Before diving too deep down the rabbit hole, we’ll start by figuring out if freelance development is right for you. To start, we’ll go through the best aspects of freelancing, followed by aspects that are more challenging or difficult. Compare these pros and cons with your current full-time salaried role and decide which one sounds best to you. The information shared here is based on my experience working as both a subcontractor via a consultancy, and as an independent freelancer working solo.
Freelancing Positives
More flexibility. For many, this is the most appealing aspect of making the leap to a freelance career. While some crave the routine that working from an office Monday to Friday provides, others chafe at the commute, long hours, and repetitive days. Even though many freelance developers often work from client offices, the change in environment is much more frequent, truncated by the shorter length of freelance engagements compared to employment contracts. Other freelancers prefer to work from home, from a coworking space, or even becoming a digital nomad.
More autonomy. As the saying goes, freelancers are their own boss. You decide your hourly rate, where you’d like to work from, and how your business will run. You decide when to work and when not to work. Depending on the client, you may get much more control over the tech stack and approach to delivering a project than you would as part of a development team. However, this level of autonomy can be challenging for people who struggle to stay motivated and on-task without the peer pressure of a team environment.
The ability to shape work around your lifestyle. I once had a colleague who would take 3 months off every year to go surfing in Brazil, then spend the remaining 9 months of the year freelancing. Contract work allowed him the flexibility to do that, but his lifestyle would have been incompatible with most full-time salaried positions.
The potential to earn more per hour than you would as a salaried employee. Freelance developers can charge between $80 – $250 an hour depending on experience and skillset (and sometimes more), rates that not many salaried developers achieve in their lifetime. However, unpaid time including marketing, admin, contract negotiations, meetings with prospective clients, sick days, vacations, and lean periods without enough clients can take the shine off high hourly rates. In the end, freelancing is often not as lucrative as it appears on the surface, particularly when freelancers have a high rate of client turnover. Freelancers who can work with repeat clients or on multi-month freelance contracts have the best chance of exceeding their earning potential as a full-time salaried employee.
The potential to expand your business. Full-time salaried employees who become overwhelmed with too much work generally have only two options: ask for more support or work increasingly long hours. Freelancers who are overwhelmed with too much work have a potentially lucrative way to deal with the situation: hire a subcontractor. This is the way that many consultancy businesses get their start: with a talented freelancer bringing others onboard to take on some of the workload and earning a cut of the subcontractor’s rates.
Choose your tech stack. If your employer asks you to use a tool or programming language that you dislike, there’s not a lot you can do about it. As a freelancer, you can choose to only work with clients who’ll allow you to use your favorite programming language and tools. You’re more likely to be starting greenfields projects than working on an existing codebase, and can therefore avoid inheriting a pile of spaghetti-code. However, this may not be true when you’re getting established as a freelancer, or during lean-times, where you may need to do whatever work is available.
Choose your own way of working. As a full-time salaried developer, you’ve likely had to conform to your team or manager’s preferred way of working. This might include project management apps that are frustrating to work with, boring (and occasionally futile) estimation sessions, and needlessly complex record-keeping and reporting requirements. This is likely to still be true if you’re a freelancer who works on client sites or embedded in client teams. However, if you’re working alone, clients generally care more about what you do rather than how you do it (even if that means their project is managed across three or four barely legible Post-It notes).
Freelancing Negatives
At this point, freelancing is probably sounding pretty great! But hold on a minute, there are a number of things that are challenging and difficult about being a freelancer. These things may or may not be deal-breakers for you.
No benefits. Sick days, annual leave, work laptops, retirement contributions, employer-paid health insurance, parental leave, gym memberships, free lunches, performance bonuses, training budgets, a company car… forget about them. Freelancers generally don’t receive any benefits from their clients other than money in exchange for services. Despite this, freelancers still get sick, need vacations, need new laptops, need health insurance, need parental leave, and all the rest. The difference is in who pays for these things. You do. Now you can probably see why that shiny $100 an hour rate soon seems less like a luxury and more like a necessity.
Potentially higher and more complex taxes. Depending on your country of residence you may have different tax obligations as a freelancer compared to as an employee. In some countries, freelancers are taxed at a slightly higher rate than employees. You’ll likely have to do much more expense tracking and receipt management than you would as a salaried employee. For example, you’ll have to remember to deduct and keep receipts for a portion of your bills, office equipment, work-related training, travel, marketing expenses, and subscriptions. To make sure you understand what your tax obligations will be as a freelancer, I’d recommend talking to an accountant if you’re seriously thinking about making the switch.
Income instability. Freelancers often talk about the “feast or famine” phenomenon. Sometimes it feels like you have far too many clients to manage, while at other times, your inbox is empty and your days are spent watching reruns of Dr. Phil. As a result, your income can fluctuate, making it difficult to plan for recurring expenses. This instability is more common for freelancers who are still getting established and haven’t had time to build up a network of repeat clients. In general, the best antidote to income instability is time. With time, you’ll develop a regular client base that will help make your income more consistent and predictable.
Avoiding ‘Clients from Hell’. It’s tempting to think that freelancing will provide a permanent escape from bad bosses, but the existence of the Clients From Hell website suggests otherwise. Most clients are lovely, but occasionally you’ll end up with a client who tries to inflate the scope of the project, questions your decisions, or expects you to be available 24/7. Another common problem that many freelancers experience is late payment, and unfortunately, chasing up payments will become part of your job. Using a platform like CodementorX can mitigate some of these issues, as clients are pre-vetted before they’re allowed to work with you.
More non-development, non-tech tasks as an indie freelancer. A general rule for many independent freelancers is that you should expect about 50% of your time to be billable. The other 50% will involve marketing, talking to potential clients, preparing quotes and estimates, drawing up contracts, attending meetings, sending invoices, chasing up payment, updating social media, tweaking your portfolio website, networking, and doing general admin and bookkeeping. Notice that those 50% are all non-development tasks, meaning that 50% of your time is likely to be spent doing things that are completely unrelated to programming. Does that bother you? If so, you’d probably be happier subcontracting for an agency or consultancy, who will take care of most of these tasks for you. The trade-off here is that subcontractors working for an agency or consultancy are paid lower hourly rates and have less flexibility than independent freelancers, as the agency needs to take their cut (often 50% or more of what the client is paying for you). Sub-contractors also have less flexibility and are usually expected to work on-site and stick to the same hours as other employers.
Risk of isolation. For some of my friends, the biggest obstacle of going freelance is the fear of isolation. As an independent freelancer you’ll often be working from home, cafes, or coworking spaces where social interaction won’t happen incidentally. If you’re flying solo on a project, you won’t get to experience the daily interactions that occur when you’re part of a team. This is often extremely off-putting for people who love the social aspect of full-time salaried work. Even if you work on-site, freelance contracts can be as short as a few days or weeks, giving you little time to form long-lasting bonds with the people you work with. In a recent survey of freelancers in the UK, almost half of the respondents said they felt that freelancing was ‘lonely’ or ‘isolating’. It’s clear that freelancers need to take proactive steps to ensure that they get adequate, satisfying social contact in the absence of a permanent set of colleagues.
It can be hard to set and stick to boundaries. While working in an office provides a natural rhythm to the workday (as well as social pressure to avoid spending the whole day watching NBA highlights on YouTube), working from home, a cafe, or a coworking space requires more self-discipline. The first kind of discipline is the discipline to work when you’re supposed to, rather than goofing off all day. The second kind is the discipline to stop working when it’s time to stop. Nobody will enforce these boundaries except for you (and possibly your significant other!).
You won’t always be able to rely on coworkers to help when you get stuck. This is more true for freelancers who work alone. What happens if you get stuck? You generally can’t ask the client for help, as they may not be technical and they might expect you to have all the answers because they see you as an expert. Instead, you’ll need to build your own support network of developers you can turn to when you need help or advice. Even the most experienced developer benefits from being able to spitball and sanity check ideas with other developers. If you don’t already have a network like this, you can get help via Codementor.
If freelancing is right for you, what next?
You’ve weighed the pros and cons and decided that becoming a freelancer developer is the right move for you. Here’s what to do next.
The first step is to assess your current financial situation. What are your current financial obligations and monthly expenses? What’s the minimum income you need to make ends meet? A spreadsheet can be helpful here. Making the switch to freelancing, or any career change, follows a general rule: as the speed of your transition increases, your level of financial risk increases. You need to find the right balance between speed and risk, and this will depend on the urgency with which you want to leave full-time salaried employment, and your financial and family situation. You have various options depending on your need for speed, and appetite for risk:
Keep working full-time and freelance on evenings and weekends.This is the safest option financially, but will take a toll on other areas of your life as you work longer hours. This may be a good option if you’re young and single, but becomes more difficult if you have less energy to burn, or a family that you need to nurture. If you go this route the idea is to transition to freelancing by gradually reducing the days that you work at your full-time salaried job. If this isn’t possible then you might consider saving up three months of your salary and using that as runway to launch your freelancing career, tiding you over while you assemble your first batch of clients. This option is arguably the safest, but also the slowest, as you’ll have less time overall to work on establishing your freelance business.
Go part-time and work on developing your freelance business the rest of the time. This might involve scaling back to part-time hours, or finding a new part-time role. Your part-time role will help make ends meet while still allowing you time to work on developing your freelance business. However, part-time roles in development are relatively rare. It may be easier to negotiate a part-time arrangement with your current employer if they sense that you might otherwise have to leave. This option is a good balance between financial safety and speed of transition.
Take a sabbatical to work on your freelance business. Some employers will allow you to take a ‘sabbatical’, a.k.a several weeks or months of unpaid leave. This provides you with a window of opportunity to try out a freelance career. If you like it, you can make the sabbatical permanent. If you don’t, you can return to your previous role.
Quit your job as soon as possible and work on developing your freelance business. This is the riskiest option, but can be viable for people who have enough savings to make it work. If you have a significant other or a family, you’ll also need to gain their support for this move. One way to reduce the risk involved with this option is to reduce your expenses as much as possible.
Ready to Start Work
If you’ve decided that freelancing is right for you, and picked an option from the list above that matches your appetite for risk, it’s time to start taking practical steps to make this move a reality.
In my next post I’ll break down how to get your first few clients as a freelance developer. Stay tuned!